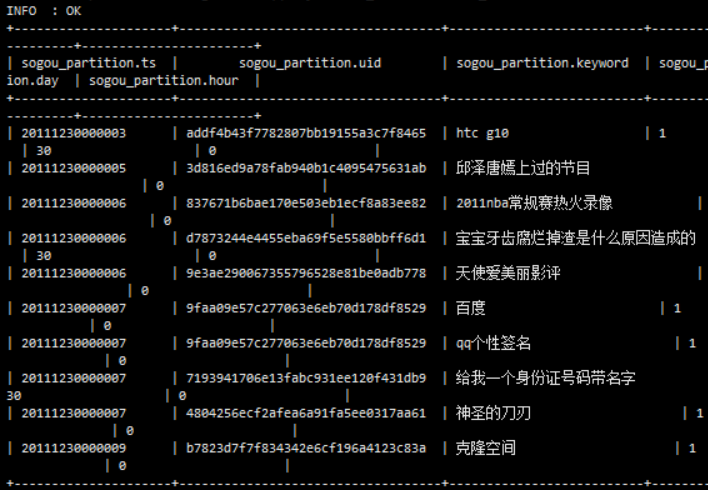
#case A when B then C when D then E else F end; select ts, uid, rank, case rank when "2" then rank+1else rank-1endfrom sogou.sogou_liangjian; +-----------------+-----------------------------------+-------+------+ | ts | uid | rank | _c3 | +-----------------+-----------------------------------+-------+------+ |20111230104333|53a3b5132bd6af7d324f3fd55d7153ba |3|2| |20111230104334|966a6bf4c4ec1cc693b6e40702984235 |4|3| |20111230104334| ae55d5e4b4f29a1221816a121e087567 |2|3| +-----------------+-----------------------------------+-------+------+
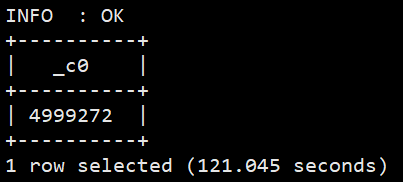
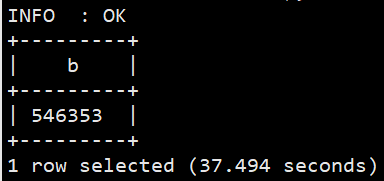
#查询关键词非空数据 selectcount(*) from sogou.sogou_ext where keyword isnotnulland keyword !='';
1 2 3
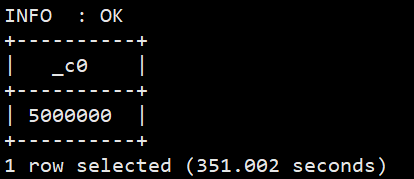
#无重复总条数(根据ts, uid, keyword, url) selectcount(*) from (select uid,count(*) from sogou.sogou_ext groupby ts,uid,keyword,url havingcount(*) =1 ) t; #需要给子表起个名
1 2
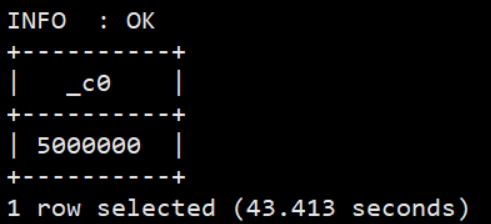
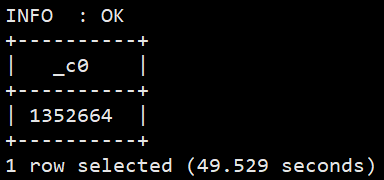
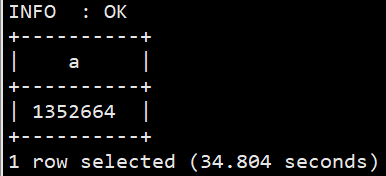
#统计独立uid条数 selectcount(distinct(uid)) from sogou.sogou_ext;
数据分析需求(2):关键词分析
1 2 3 4
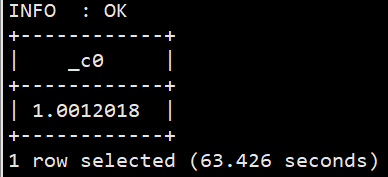
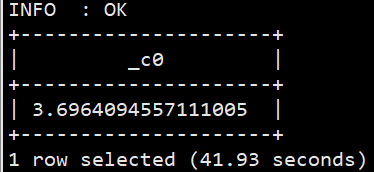
#查询关键词平均长度 selectavg(a.cnt) from (select size(split(keyword,' s+')) as cnt from sogou.sogou_ext) a; #由于split函数不支持矢量计算,需要先关闭该功能 set hive.vectorized.execution.enabled=false;
1 2
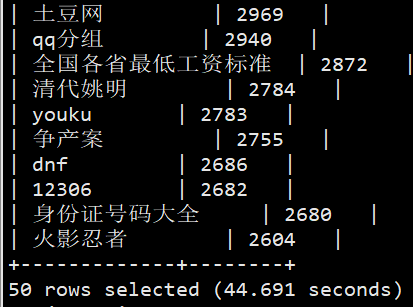
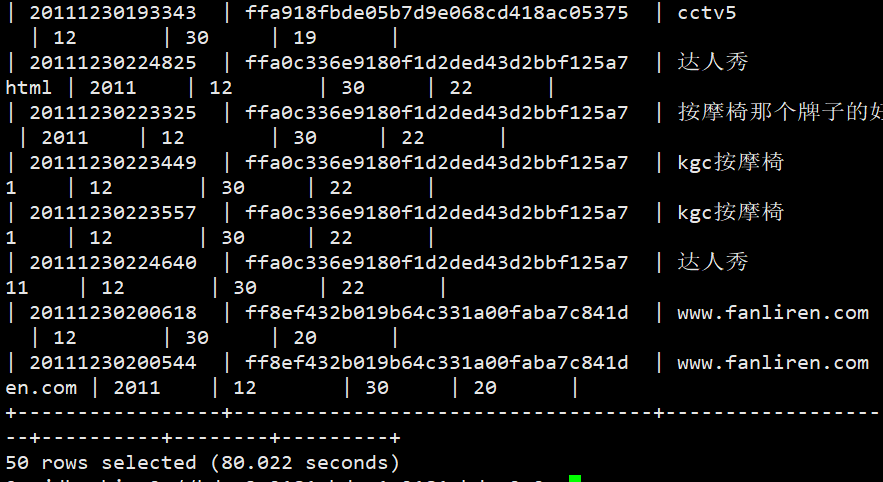
#查询频度排名前50 select keyword,count(*) as cnt from sogou.sogou_ext groupby keyword orderby cnt desc limit 50;
数据分析需求(3):UID分析
1 2 3
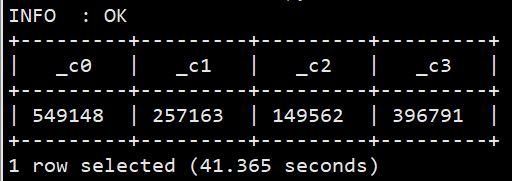
#为了统计UID的查询次数分布(查询1次的UID个数…查询n次的UID个数),这里我们列出查询1次、2次、3次和大于3次的UID个数 selectsum(if(uids.cnt=1,1,0)),sum(if(uids.cnt=2,1,0)), sum(if(uids.cnt=3,1,0)), sum(if(uids.cnt>3,1,0)) from (select uid, count(*) as cnt from sogou.sogou_ext groupby uid) uids;
1 2
#统计UID平均查询次数 selectsum(a.cnt)/count(a.uid)from(select uid,count(*)as cnt from sogou.sogou_ext groupby uid) a;
1 2 3 4 5 6 7 8
#统计查询次数大于2次的用户占比: #先统计B:UID总数 selectcount(distinct(uid)) as A from sogou.sogou_ext; #统计查询A:次数大于2的UID个数 selectcount(a.uid) as B from (select uid,count(*) as cnt from sogou.sogou_ext groupby uid having cnt>2)a; #占比结果是C=B/A #查询次数大于2次的数据如下 select b.*from(select uid,count(*) as cnt from sogou.sogou_ext groupby uid having cnt >2) a join sogou.sogou_ext b on a.uid=b.uid limit 50;
数据分析需求(4):用户行为分析
1 2 3 4 5
#点击次数与rank之间的关系 selectcount(*) from sogou.sogou_ext where rank <11; +----------+ |4999869| +----------+
1 2 3 4 5
#直接输入url进行查询的比例 selectcount(*) from sogou.sogou_ext where keyword like'%www%'; +--------+ |73979| +--------+
1 2 3 4 5
#用户访问的网站包含用户输入的url类型关键词 selectsum(if(instr(url,keyword)>0,1,0)) from (select*from sogou.sogou_ext where keyword like'%www%')a; +--------+ |27561| +--------+
1 2 3 4 5 6 7 8 9
#查询独立用户行为 select uid, count(*)as cnt from sogou.sogou_ext where keyword like'%仙剑奇侠传%'groupby uid having cnt >3; +-----------------------------------+------+ | uid | cnt | +-----------------------------------+------+ |265f1fa26029c058c695ecc7ee4bad01 |4| |2b136abffd8f0dd38d97a52a7e50f7fb |4| |40aa046859609c25b3914ac9f2735c5c |5| |653d48aa356d5111ac0e59f9fe736429 |9|